基于贡献分配的开源软件核心开发者
X-lab 周一论文分享,唐烨男
目录
- 为什么分享这篇论文
- 寻找核心开发者的3个类型阶段
- 实验框架
- 数据集介绍
- 核心文件组
- 贡献分配算法
- 实验结果
- 支持向量机分类预测
- 论文“盲点”
- 收获与启发
为什么分享这篇论文
1
访谈问卷类需要深厚的底蕴
暂时难以驾驭
客观计算类的更符合个人兴趣
2
希望能运用到所有仓库
每个Repo都有机会看到自己的数据
3
也许可以从更微观的角度来衡量贡献者
基于GitHub日志 → 基于.git目录
寻找核心开发者的3个类型阶段
1
统计计数阶段
2
网络分析阶段
e.g.实验室的贡献者/仓库异构网络?
3
定量分析阶段
实验框架
Linux,Python,R
9个Apache项目
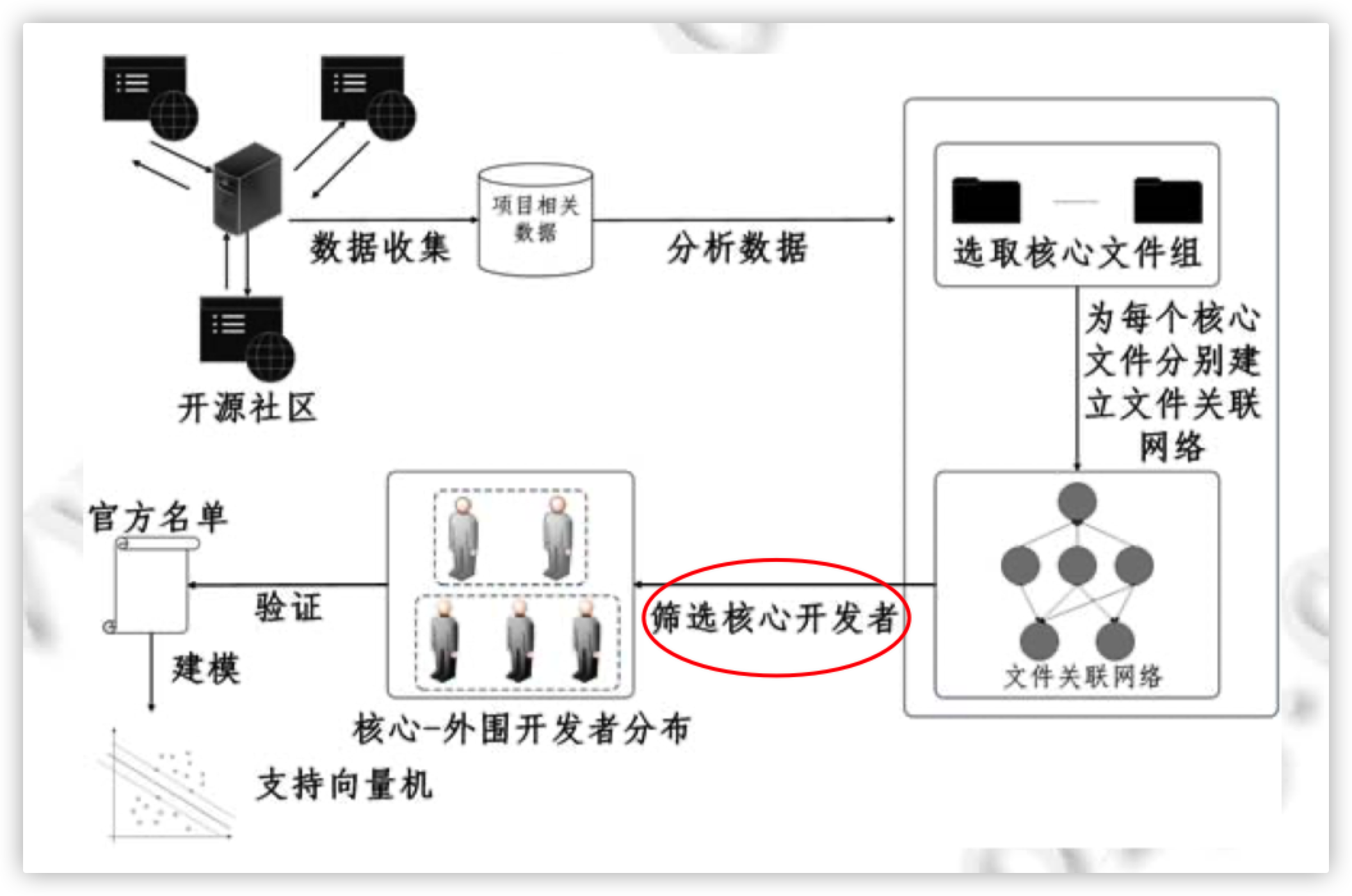
核心文件组 → 核心开发者
贡献度分配算法
...
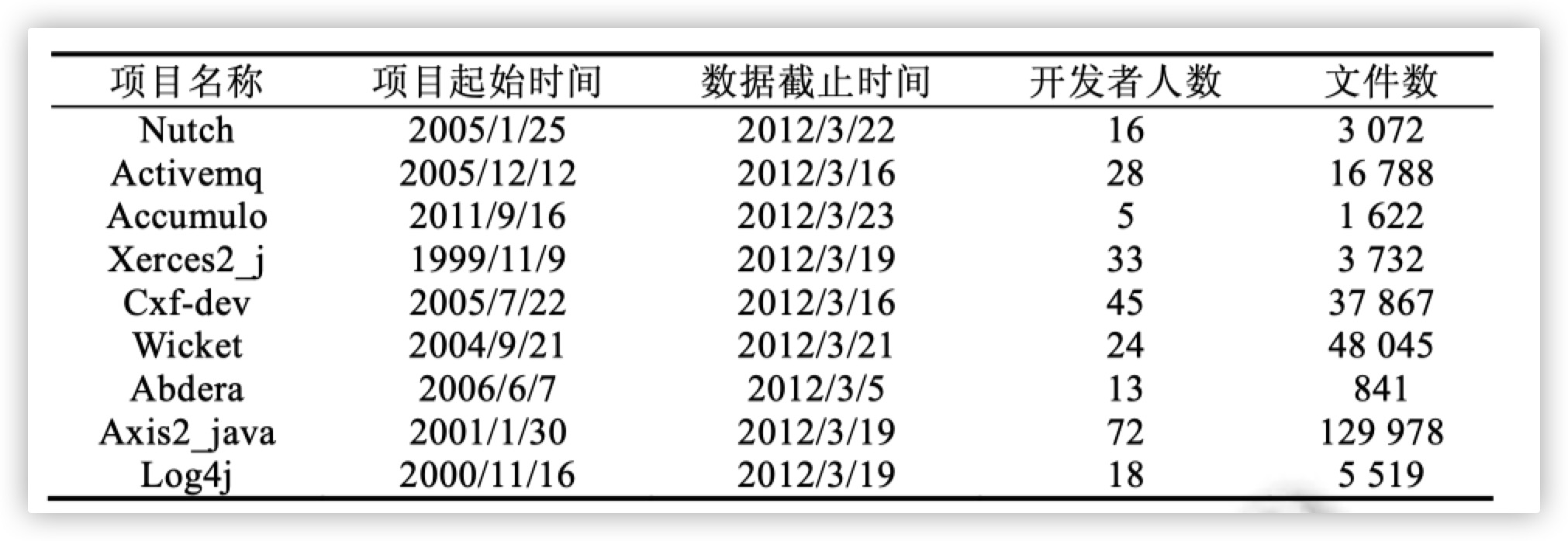
数据集
9个Apache项目
全是Java项目
两部分数据信息
1
开发者开发记录
总编译次数
具体操作文件
总的代码行数
与其他开发者之间邮件记录
具体操作文件
总的代码行数
与其他开发者之间邮件记录
2
源文件之间相互调用记录
相互调用情况
调用次数
核心文件组
- 核心的文件 → 核心的开发者
- 占引用次数和前90%的文件
- 后期加入、被引用次数不多但在加入后短期被频繁编译的文件
贡献度分配算法
input
核心文件组
文件引用关系
文件作者列表
output
贡献度份额向量c
(1个m维向量)
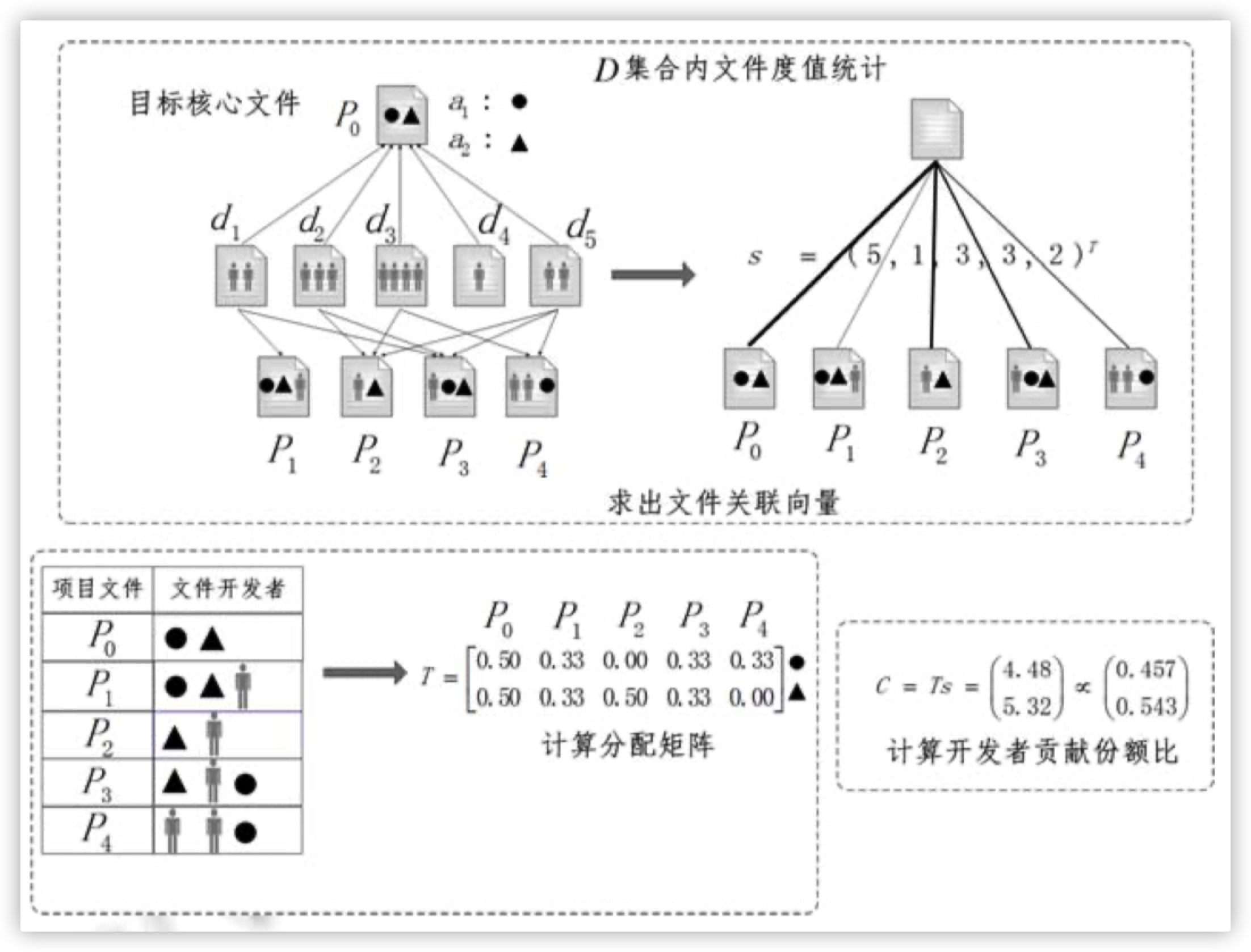
步骤
for p in 核心文件组:
建立p的3层关联网络
求p的贡献度份额向量c
所有开发者对核心文件组
的贡献度份额向量
= 所有c的平均值
(选取贡献度总和的前80%
作为核心开发者)
p的3层关联网络
第1层
p本身(图中P0)
第2层
调用p的所有文件d
第3层
所有d调用的非核心文件
求p的c
向量集合s
第1、3层中各文件被所有d调用的次数
分配矩阵T
每行代表p的其中一个作者在第1、3层各文件中的人头占比
c = Ts
求所有c的平均值
Q: 每个c的长度不相等,怎么办?
A: 假设每个核心文件的作者集合是所有的开发者,这样可以统一长度且不影响结果
核心开发者
c中贡献度总和的前80%覆盖的开发者为核心开发者
全局影响因子$\lambda$
仅仅按人头比来计算贡献度易造成偏差
故引入全局影响因子$\lambda$
${c_i}^{'} = {c_i}{\lambda_i}$
${\lambda_i} = \frac{I_i}{N_i}$
其中,$I_i$是开发者$i$编辑过的所有文件在整个项目中被调用的次数,$N_i$是开发者$i$在整个项目中编辑过的文件数
实验结果
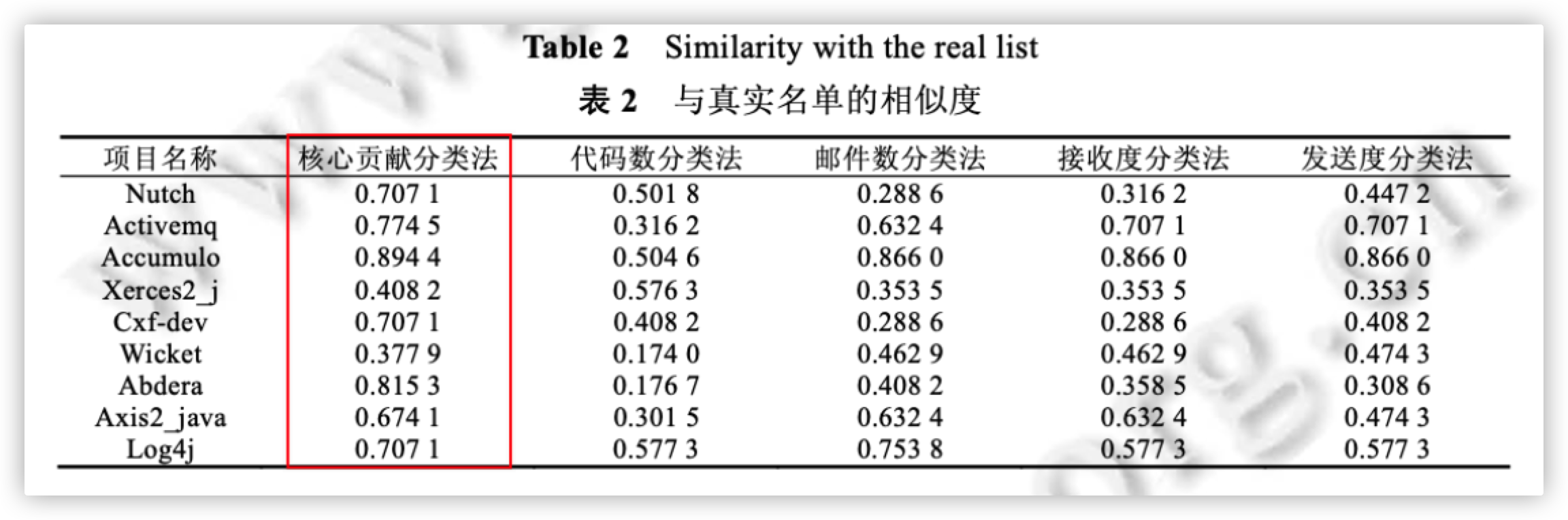
从实验结果可以看出,与传统分类方案相比,基于文件贡献的分类法在总体上有着更高的真实名单相似度
支持向量机分类预测
简单来说,在核心贡献度这一个指标的基础上
再综合若干个其他指标,可以让核心开发者的识别更准确
所以多维度综合分析效果是更好的
论文“盲点”
- 数据集
- 对数据集几乎没有介绍
- 文件重命名和路径变化如何处理?
- 文件的共同作者如何确定?
- 缺乏对文件引用网络构造过程的介绍
- 不同的语言有不同的引用机制
- 不在引用网络中但也很核心的文件
收获与启发
- 逛ASF的收获
- ASF项目的主战场大多不在GitHub
- GitHub上的仓库只是个镜像
- Issue追踪用Jira和Bugzilla
- 因此不适用基于GitHub日志的分析系统
- 微观角度的补充
- 基于GitHub日志的方法是宏观的
- 基于文件(Git历史记录)的方法是微观的
- 两者也许能结合起来
- Snoot
- 与hypercrx是同类项目
- 其订阅收费模式可供参考
- 用户反馈机制
- 多套参数多套排名结果,hypercrx进行呈现
- 用户可以打分反馈到模型的参数上